|
|

Recherche personnalisée
|
Dictionnaire technique de materiel-informatique.be: les définitions classées par thématique: |
Architecture superpipeline
Amélioration du pipeline, les processeurs superpipeline découpent le traitement d'une instruction assembleur en 7 niveaux. Si l'architecture pipeline traite 3 instructions en 6 temps d'horloge, cette structure interne permet le traitement de 7 instructions en 13 temps d'horloge. Le fonctionnement est lié au cache L1, notamment dans les Pentium IV.
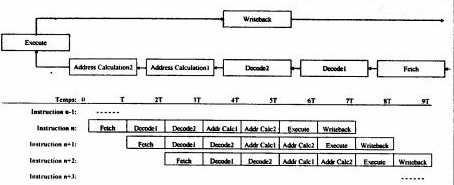 Dans le cas d'une structure standard de
microprocesseur comme le Z80
ou le 8088, le traitement d'une
instruction ne débute que lorsque la précédente est totalement exécutée. Le
pipeline découpe la séquence en 4 parties:
Dans le cas d'une structure standard de
microprocesseur comme le Z80
ou le 8088, le traitement d'une
instruction ne débute que lorsque la précédente est totalement exécutée. Le
pipeline découpe la séquence en 4 parties:
- chargement de l'instruction dans le processeur, utilisation des bus externes
- décodage de l'instruction à l'intérieur du microprocesseur
- exécution de la commande
- transfert du résultat sur les bus
Dans le cas d'un super-pipeline, on utilise 7 étapes ou plus:
- Pré extraction, transfert des données sur les bus internes
- Premier décodage d'instruction
- Deuxième décodage d'instruction
- Première génération d'adresse
- Deuxième génération d'adresse de retour
- exécution de l'instruction
- transfert des données via l'adresses prégénérée (4 et 5)
Le P3 ou l'Athlon utilise un pipeline à 10 niveaux, les P4 (architecture Netburst) de 20 ou 21 niveaux suivant les modèles.
Définitions connexes: superscalaire
Dernière mise à jour, le 26/01/2021| © Tous droits réservés, reproduction interdite sans accord écrit de materiel-informatique.be. Les marques citées sont propriétés des constructeurs et éditeurs. |